You search for 'roam like' on the Internet…
🔍 Web results by Marginalia • Google • Bing • DDG • YouTube • Maps • GitHub • Bluesky • Fediverse
Tip: Click an active tab again to open it in a new window. If a tab appears empty, the provider may not allow embedding.
x
🤖 AI generations by Mistral • Gemini • ChatGPT • Claude
This is an Agora Assistant trying to help you navigate generated by the provider above.
x
This you find in the Agora of Flancia…
Loading Wikimedia Commons...
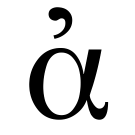
Loading Wikimedia content...
Loading Agora node...
💬 Stoas for [[roam like]]
Stoas are shared spaces where interested people can meet and collaborate.
x
📖 Shared document at https://doc.anagora.org/roam-like
This is a shared document for [[roam like]] where you can collaborate with others.
📹 Meeting space at https://jitsi.meet.coop/roam-like
This is a meeting space in [[roam like]] which you can use to talk to like-minded people.
🔎 Full search for 'roam like'
These are all Agora resources which contain matches for your search.
Searching the Agora for matches...